
Mit dem Release von Windows Server 2016 wird Microsoft eine neue Version des Dateisystems „Resilient File System“, kurz ReFS, veröffentlichen. ReFS hat Einzug in den Windows Server unter 2012 gehalten, dort war es in Version 1 verfügbar. Kaum eine Software und kaum ein Hersteller hat das neue Dateisystem vollständig unterstützt; wir bekamen häufig Aussagen wie „Das kann funktionieren, muss aber nicht; probieren Sie es aus.“. Wenn es zum Beispiel darum ging sehr große Volumes anzulegen, wie z.B. für Backup-Speicher. Mit Windows Server 2016 wird sich dies nun ändern, Microsoft hat im Hintergrund viel gearbeitet und die Versionsnummer auf eine 3 heraufgestuft. Mit dieser neuen Version kommen nun etliche Verbesserungen und Neuerungen mit, auf die ich im Laufe des Artikels eingehe und kurz erläutere. Im zweiten Teil zeige ich die Mehrwerte auf, die sich allein durch die Nutzung von dem neuen Dateisystem ergeben.
Verbesserungen und Neuerungen
Bei der Nutzung von ReFS gegenüber NTFS gibt es einige Vorteile. Die folgenden Beschreibungen beziehen sich ausschließlich auf Version 3 von ReFS unter Windows Server 2016, vorherige Versionen werden nicht betrachtet:
Maximalwerte
Ein Volume kann bis zu einem Yottabyte groß werden. Das sind 1 000 000 000 000 000 000 000 000 Bytes oder eine Milliarde Petabytes. Jede Datei auf dem Volume kann bis zu 16 Exabyte groß werden. Diese Speichermenge brauchen wir aktuell jedoch noch nicht, das Dateisystem ist aber schonmal gerüstet.
Die Arbeit mit Metadaten
Viele Datei-Operationen werden nicht mehr direkt ausgeführt (z.B. die Erstellung von einer VHDX mit fester Größe), sondern es wird per Metadaten-Operation gemacht. Dies beschleunigt viele Operationen ungemein.Wo genau diese Funktion Verbesserungen bringt, sehen wir später im zweiten Teil.
Block Cloning
Bei diesem Vorgang kopiert das Dateisystem selbst einen Teil der Daten statt der Applikation selbst. Es gibt bei diesem Vorgang einige Voraussetzungen, z.B. das der geclonte Bereich nicht größer als 4 GB sein darf (Achtung: Nicht die Datei selbst ist hiermit begrenzt, sondern nur der jeweilige Bereich, der geclont wird). Weiterhin müssen die Dateien (Quelle und Ziel) auf dem gleichen Volume liegen, sonst funktioniert der Vorgang nicht. Weitere Informationen sowie eine sehr gute Grafik wie der Cloning-Prozess abläuft, finden sich bei Microsoft selbst: Microsoft MSDN: Block Cloning
Schutz gegenüber logischen Fehlern
Alle Metadaten, die auf dem Volume vorhanden sind, werden mit einer Checksumme belegt, geprüft und bei einem Missmatch automatisch repariert. Dies sorgt dafür, dass nicht separat und manuell ein ChkDsk ausgeführt werden muss. Benutzerdaten können optional ebenfalls mit diesen Prüfsummen vor einem Ausfall geschützt werden, diese Funktion hört auf den Namen Integrity Stream. Der Schutz kann entweder für das gesamte Volume, für einzelne Ordner oder für einzelne Dateien konfiguriert werden. Die Aktivierung dieser Funktion bedingt (vermutlich) Storage Spaces-Technologie im Hintergrund und führt zur einer Reduzierung der Performance.
Funktionen, die (noch) nicht enthalten sind
Da ich einen Teil der Neuerungen aufgeführt habe, hier noch ein paar Worte zu Funktionen, die nicht oder noch nicht in ReFS enthalten sind. Dies kann für gewisse Einsatzzwecke egal sein, für andere sind diese Funktionen allerdings essentiell.
- Keine Unterstützung von 8+3 Dateinamen ;)
- Keine NTFS Komprimierung
- Keine Nutzung von Encrypted File System (EFS)
- Keine Unterstützung und Nutzung von Quotas
- Keine Deduplizierung
- Keine Boot-Möglichkeit von einem ReFS-Volume
Die Mehrwerte bei der Nutzung von ReFS als Ablage für Hyper-V VMs
Wird das lokale Laufwerk oder das Cluster Shared Volume mit ReFS unter Windows Server 2016 formatiert, ergeben sich zahlreiche Vorteile bei dem Betrieb von VMs auf diesem Volume.
[ms_alert icon=“fa-exclamation“ background_color=“#f5f5f5″ text_color=““ border_width=“0″ border_radius=“0″ box_shadow=“no“ dismissable=“no“ class=““ id=““]Die Nutzung von ReFS-formatierten Volumes in einem Failover Cluster als Cluster Shared Volumes führt zu einem umgeleiteten Traffic, da die Daten von jedem Knoten nicht direkt geschrieben werden können, sondern erst zum Besitzer des Datenträgers geschickt werden. Dies führt in einigen Fällen zu nicht gewollten und nicht berücksichtigten Traffic zwischen den Knoten und somit zu einem möglichen Flaschenhals. Wenn jeder Knoten direkt auf seinen Datenträger schreiben soll, muss NTFS als Dateisystem genutzt werden.[/ms_alert]Die Erstellung von VHD oder VHDX-Dateien
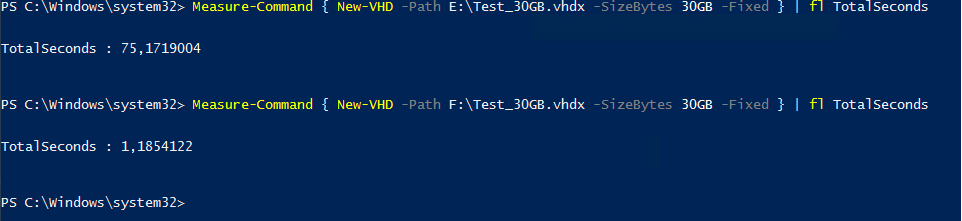
Bei der Erstellung von virtuellen Festplatten-Dateien gibt es unter NTFS immer wieder den Nachteil, dass dieser Vorgang recht lange dauern kann. Werden die Dateien mit einer festen Größe angelegt, wird die Datei nach der Erstellung „durchgenullt“. Hierbei wird der gesamte Speicherplatz mit Nullen geschrieben, dies kann bei mehreren hundert Gigabyte oder teilweise Terabyte schon einige Zeit in Anspruch nehmen. Unter ReFS ist dieser Vorgang eine Metadaten-Operation und dauert ca. eine Sekunde, unabhängig von der Größe der Datei. Das Dateisystem deklariert einen gewissen Bereich als belegt, das war schon alles.
Testen wir das Ganze einmal. Auf einem Windows Server 2016 TP5 habe ich zwei Volumes erstellt, basierend auf zwei SSDs aus unserem Hyper-V Powerkurs. Volume E ist mit NTFS formatiert, Volume F mit ReFS.

Nun legen wir auf jedem der Volumes nacheinander eine 30 GB große VHDX-Datei an und messen die benötigte Zeit:
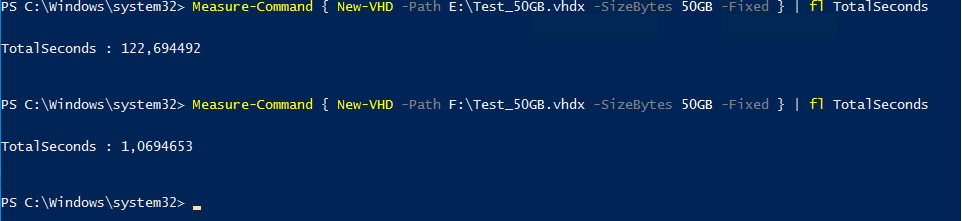
Mit einer 50 GB großen Datei sieht es wie folgt aus:
Hyper-V Checkpoints (ehemals Snapshots)
Die IO-Belastung bei der Nutzung von Hyper-V Checkpoints wird durch das neue Dateisystem enorm verbessert. Da Checkpoints nicht nur manuell erstellt werden können, sondern auch unter anderem bei der Erstellung von einem Backup zur Anwendung kommen können, werden diese recht häufig genutzt. Ein Checkpoint funktioniert wie folgt:
Eine virtuelle Maschine benutzt eine oder mehrere VHD oder VHDX-Dateien. Diese Dateien werden lesend und schreibend genutzt, vorhandene Daten werden gelesen oder verändert und neue Daten werden geschrieben.

Wird nun von der VM ein Checkpoint erstellt, werden die aktiv genutzten VHD(X)-Dateien geschlossen, es wird pro Datei eine zugehörige AVHD(X)-Datei erstellt (Hierbei handelt es sich um eine differenzielle Datei, die jeweils auf die ursprüngliche Datei verweist) und diese neue Datei wird nun für neue und geänderte Daten genutzt.
Solch ein Checkpoint wird seit Windows Server 2012 R2 zum Beispiel bei jedem VM-Backup gemacht, der erstellt wird. Nach dem Backup wird der Checkpoint wieder aufgelöst. Der Auflösungsprozess sieht unter NTFS anders aus als unter ReFS:
Checkpoint auflösen unter NTFS
Unter NTFS müssen die Daten, die in der AVHDX-Datei vorhanden sind, über die Daten in der VHDX geschrieben werden. Dieser Vorgang benötigt den doppelten Speicherplatz der AVHDX-Datei, da dieser Vorgang mit einer Kopie gemacht wird und dadurch abgebrochen bzw. unterbrochen werden könnte. Durch das Kopieren der Daten dauert dieser Vorgang, abhängig von Größe und Performance des Speichers im Hintergrund, mehrere Minuten bis hin zu Stunden. Je länger der Checkpoint vorhanden war, desto größer sind in der Regel die AVHDX-Dateien. Im Hintergrund wird der Speicherort der Dateien auf Blockebene geändert, die geänderten Blöcke der AVHDX-Datei werden auf die veralteten Blöcke der VHDX-Datei kopiert. Der Merge-Vorgang führt zu einem erhöhten IO-Verhalten auf dem Volume, der je nach Storage-System zu einer Beeinträchtigung der aktiven VMs führt.
Checkpoint auflösen unter ReFS
Wenn Sie ReFS einsetzen, gibt es keine wirklichen Bewegungen auf dem Volume. Wird ein vorhandener Checkpoint aufgelöst, werden keine Daten auf dem Volume von Platz A (die Daten in der AVHDX-Datei) an Platz B (die VHDX-Datei) verschoben, sondern es erfolgt eine „Verpointerung“ der Daten. Die alten Daten in der VHDX-Datei werden auf dem Dateisystem als ungültig deklariert und die genutzten Daten in der AVHDX-Datei werden als weiterhin gültige Daten einfach weiter benutzt, ohne das der physische Speicherplatz verändert wird. Dies führt dazu, dass das Entfernen von einem Checkpoint innerhalb weniger Sekunden möglich ist, egal wie groß die gemachten Änderungen sind. Da kaum Daten geschrieben werden, gibt es bei diesem Vorgang keinen großen (negativen) Einfluss auf die Performance von dem Volume.